直感的に操作できる学習環境
LGTM Easy Trainer
LGTM Easy Trainer」では、所定の形式のCSVファイルを読み込ませて、画面の指示に従っていくだけで、あなただけの特化言語モデルを作成できます。
直感的な操作
簡単なデータセット
圧倒的な学習スピード
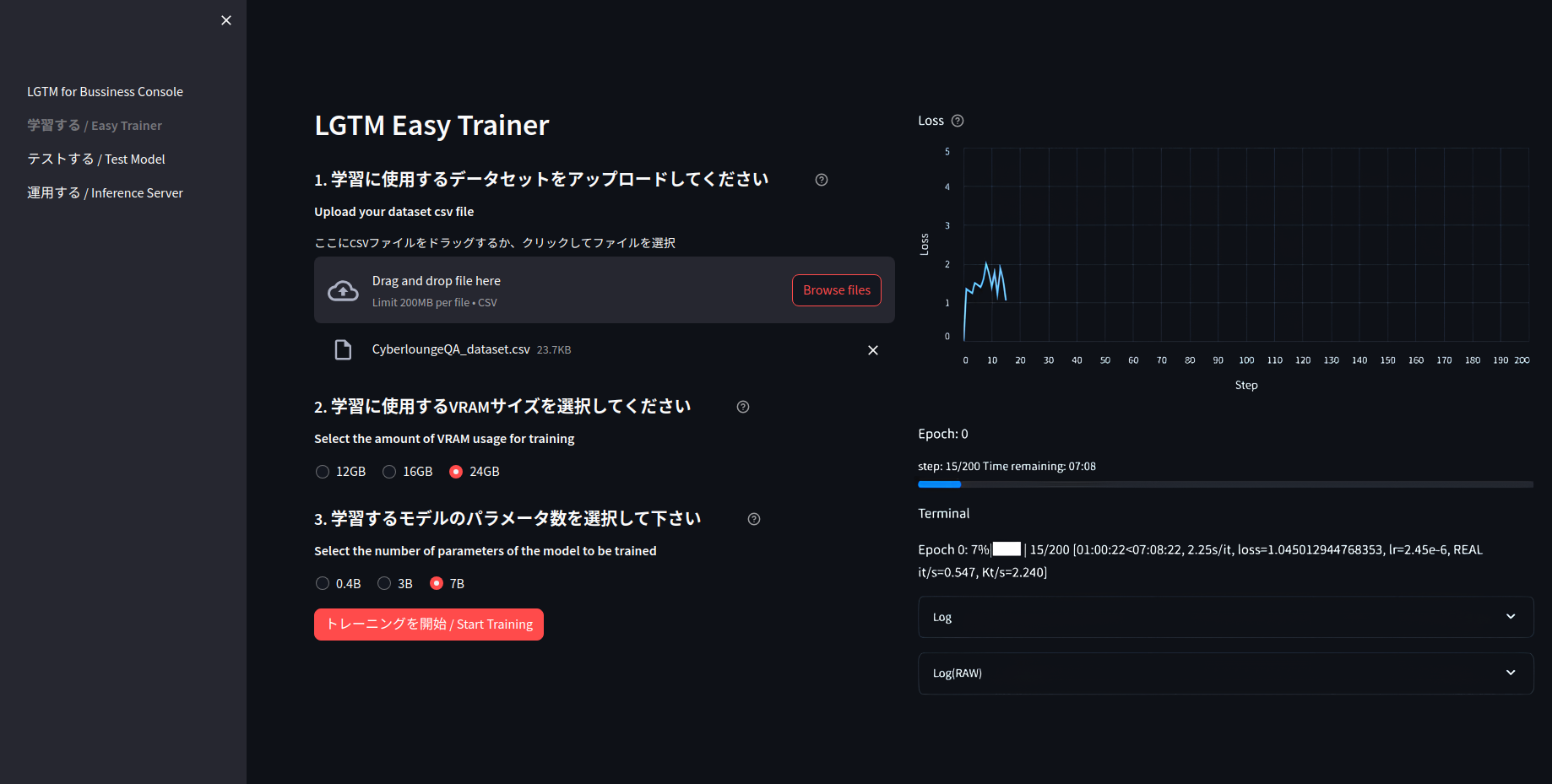
検証日:2024年3月19日時点
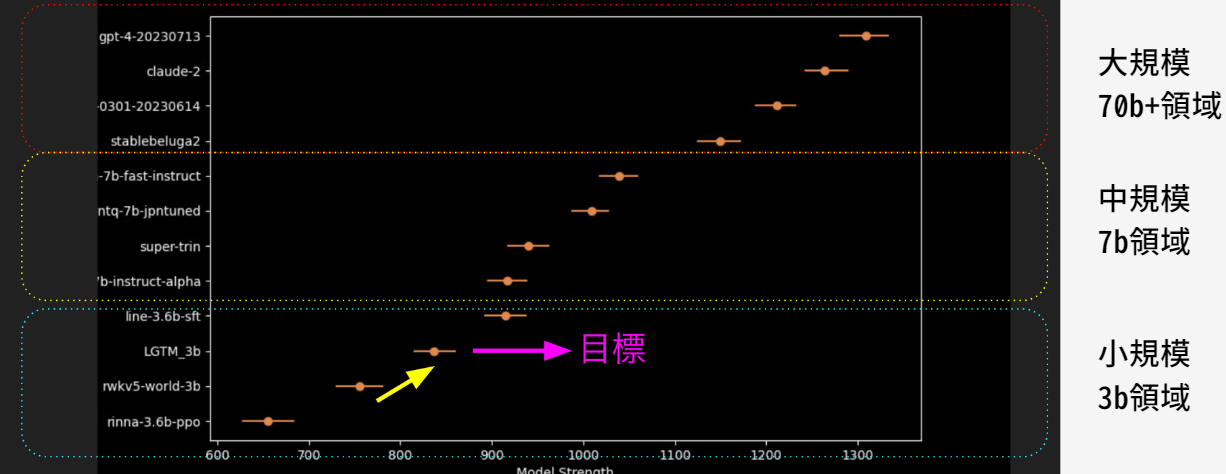


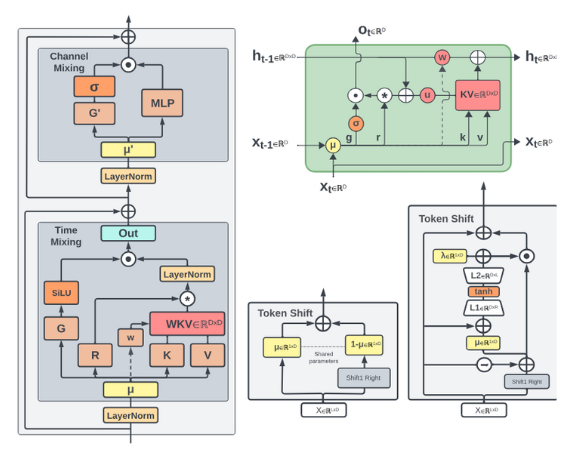
図. モデル構造
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence(https://arxiv.org/abs/2404.05892)